Designing a Proximity Service—a system that allows users to discover nearby businesses or points of interest—is a common and challenging question in system design interviews. This comprehensive guide will walk you through the key components, design decisions, and trade-offs involved in building a scalable and efficient proximity service, similar to those used by platforms like Yelp, Google Maps, and Uber.
🧭 Understanding the Problem
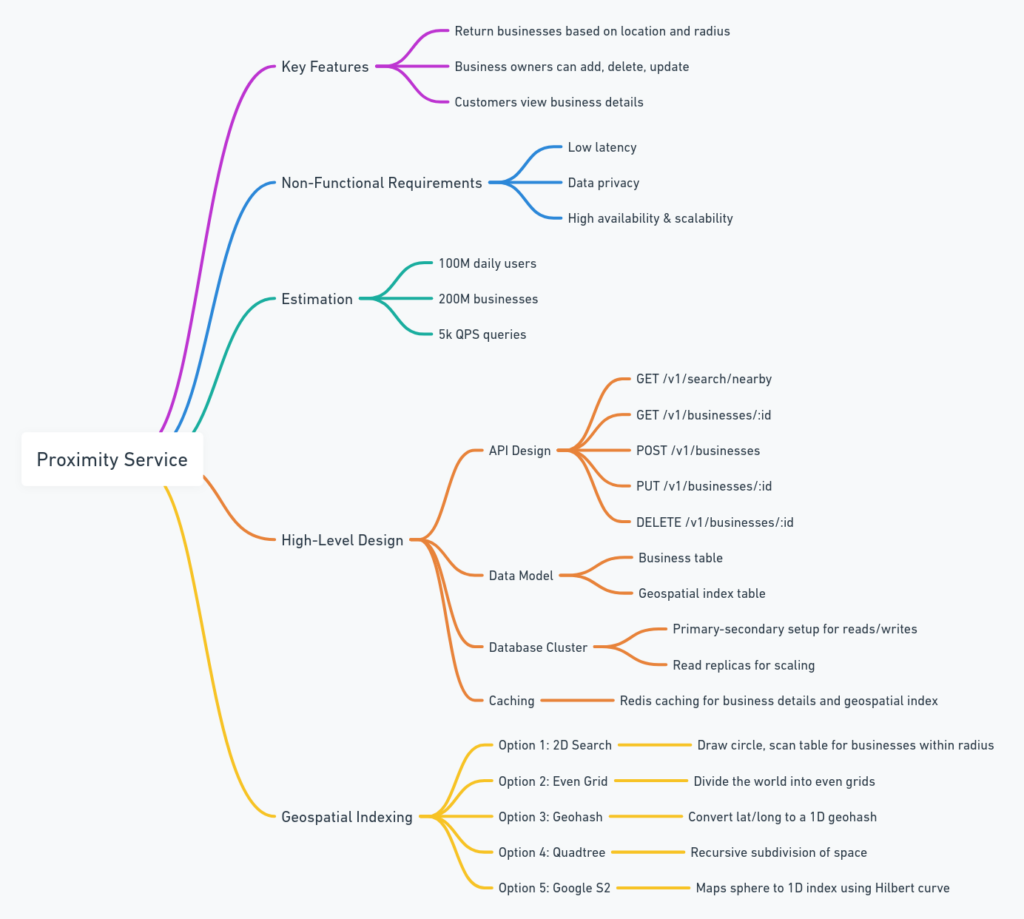
A proximity service enables users to find entities (e.g., restaurants, gas stations) within a certain radius of their current location. The primary challenge lies in efficiently querying and retrieving relevant data from potentially massive datasets, ensuring low latency and high accuracy.
Key Requirements
Functional Requirements:
- Search for businesses within a specified radius.
- View detailed information about a business.
- Allow business owners to add, update, or delete their listings. (Examples of Proximity Services. | Download Scientific Diagram)
Non-Functional Requirements:
- Low latency responses.
- High availability and scalability.
- Compliance with data privacy regulations (e.g., GDPR, CCPA). (GitHub – karanpratapsingh/system-design)
🏗️ High-Level System Design
The system can be broadly divided into two services:
- Location-Based Service (LBS):
- Handles proximity searches.
- Stateless and read-heavy, making it suitable for horizontal scaling.
- Business Service:
- Manages CRUD operations for business listings.
- Write operations are less frequent but require consistency. (Caching patterns – Database Caching Strategies Using Redis)
A Load Balancer distributes incoming requests between these services. Data is stored in a Database Cluster with a primary-secondary setup to separate read and write operations.
🗺️ Geospatial Indexing Techniques
Efficient spatial querying is crucial. Two primary techniques are:
1. Geohashing
Geohash encodes latitude and longitude into a short string of characters, dividing the world into a grid. Nearby locations share similar prefixes, enabling quick proximity searches.
Advantages:
- Simple to implement.
- Efficient for fixed-radius searches.
- Compact representation suitable for indexing. (Geohash or Quadtree? Ready, Set, Go! for System Design Interviews | by …)
Challenges:
- Boundary issues where nearby points fall into different geohashes.
- Fixed precision may not adapt well to varying data densities.
Example: Searching for businesses within a 1km radius involves identifying the geohash of the user’s location and its neighboring geohashes to ensure comprehensive coverage.
2. Quadtree
A Quadtree recursively divides a two-dimensional space into four quadrants or regions. This structure adapts to data density, offering finer granularity in dense areas.
Advantages:
- Dynamic precision based on data distribution.
- Efficient for range and nearest-neighbor queries.
Challenges:
- More complex to implement and maintain.
- Can be memory-intensive. (A distributed database load-balancing architecture with ShardingSphere …, System Design: Geohashing and Quadtrees – DEV Community)
Example: In urban areas with high business density, the Quadtree subdivides more deeply, allowing precise searches, while in rural areas, fewer subdivisions suffice.
🧪 Caching Strategies
To enhance performance, especially for read-heavy operations, caching is essential.
Geohash to Business IDs:
- Caches mappings from geohash regions to lists of business IDs.
- Speeds up the initial retrieval of nearby businesses. (6 common caching design patterns to execute your caching strategy — Momento)
Business ID to Business Details:
- Caches detailed information for each business.
- Reduces database hits for frequently accessed businesses.
Note: Using raw latitude and longitude as cache keys is discouraged due to potential inaccuracies and low cache hit rates.
🔄 Handling Data Updates
Given that real-time updates are not a strict requirement, the system can employ a nightly batch job to process additions, deletions, or modifications to business listings. This approach simplifies cache invalidation and ensures data consistency across services.
🌐 Deployment and Scalability
- Multi-Region Deployment:
- Deploying services across multiple regions reduces latency and improves availability.
- Database Scaling:
- Sharding the business data based on business IDs.
- Using read replicas to handle increased read traffic.
- Load Balancing:
- Distributes incoming traffic evenly across service instances.
📚 Further Reading and Resources
- Geohashing and Quadtrees for Location-Based Services
- Designing Proximity Service (Yelp)
- System Design Interview Guide – Ace Your FAANG-Scale Interview
- System Design Interview: Yelp or Nearby Proximity Service
🎯 Conclusion
Designing a Proximity Service encompasses various system design principles, from efficient spatial indexing to robust caching mechanisms. Understanding the trade-offs between different approaches, such as Geohash and Quadtree, and implementing effective caching strategies are crucial for building scalable and responsive systems. By mastering these concepts, you’ll be well-equipped to tackle system design interviews and real-world challenges alike.
Note: For a visual walkthrough of designing a proximity service, you might find this video insightful:
Proximity Service – System Design Interview Question
Overview of Proximity Service
Some genuinely rattling work on behalf of the owner of this website , absolutely outstanding articles.